RLBC Overview
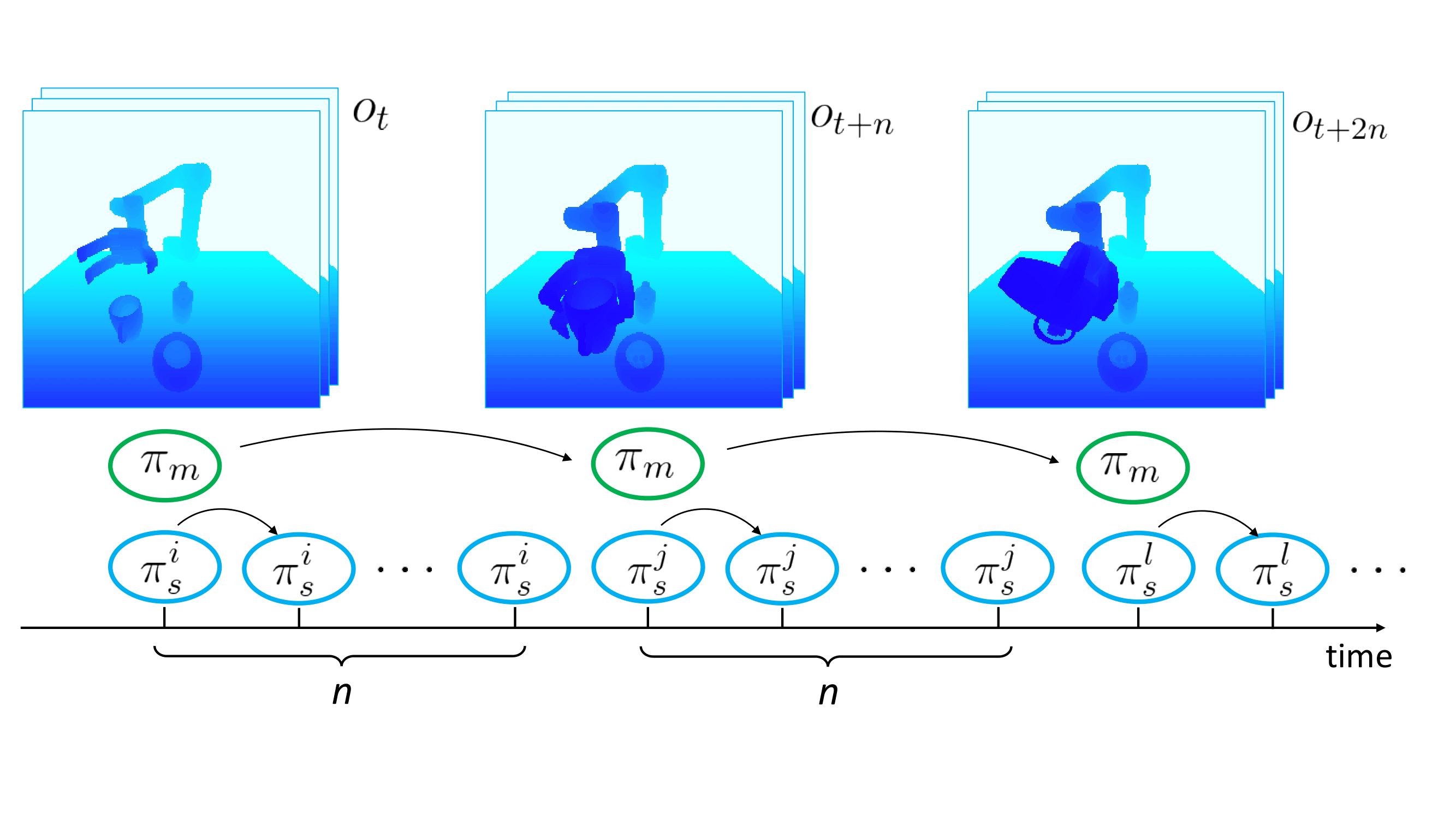
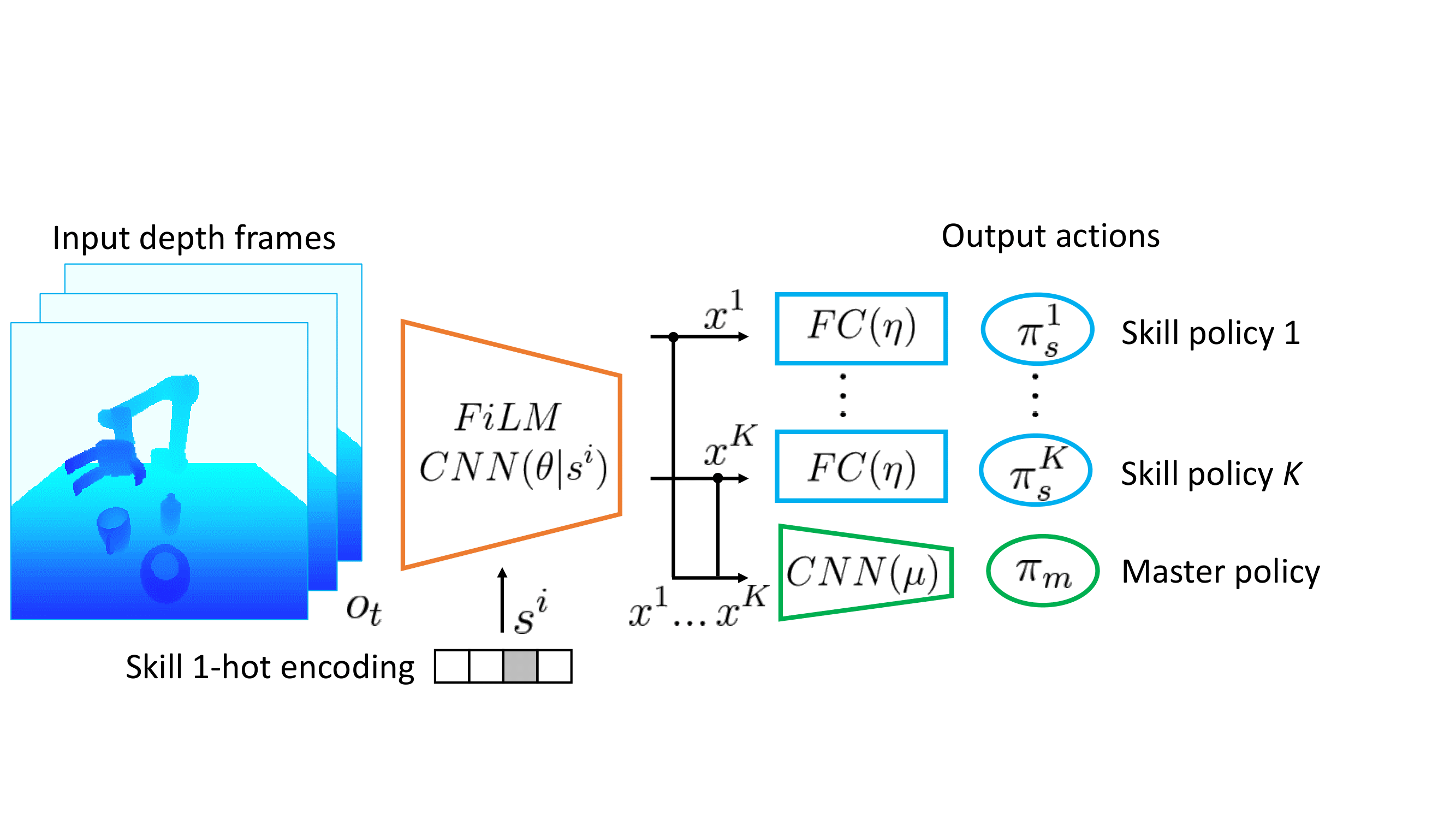
Illustration of our approach. (a): The master policy is executed at a coarse interval of n time-steps to select among K skill policies. Each skill policy generates control for a primitive action such as grasping or pouring. (b) FiLM CNN architecture conditions the network on performing a given skill, which permits learning a shared representation of all skills along with visual features that can be used for master task planning.
MImE Environments



MImE is composed of 3 robotic environments for manipulation. In every environments, the agent controls the robot end-effector and observes the environment through a camera placed in front of the robot. The goal of the agent is to output the correct sequence of actions to perform the task at hand. In UR5-Pick, a cube is on the table and the goal is to grasp a cube and lift it in the air. In UR5-Bowl, a cube and a bowl are on the table, the agent has to put the cube into the bowl. In UR5-Breakfast, the goal is to prepare a simple breakfast, a bottle and a cup are on the table and the goal is to pour the two containers in the bowl without spilling drops.