Goal-Conditioned Reinforcement Learning
with Imagined Subgoals
International Conference on Machine Learning (ICML), 2021
Abstract
Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don’t require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
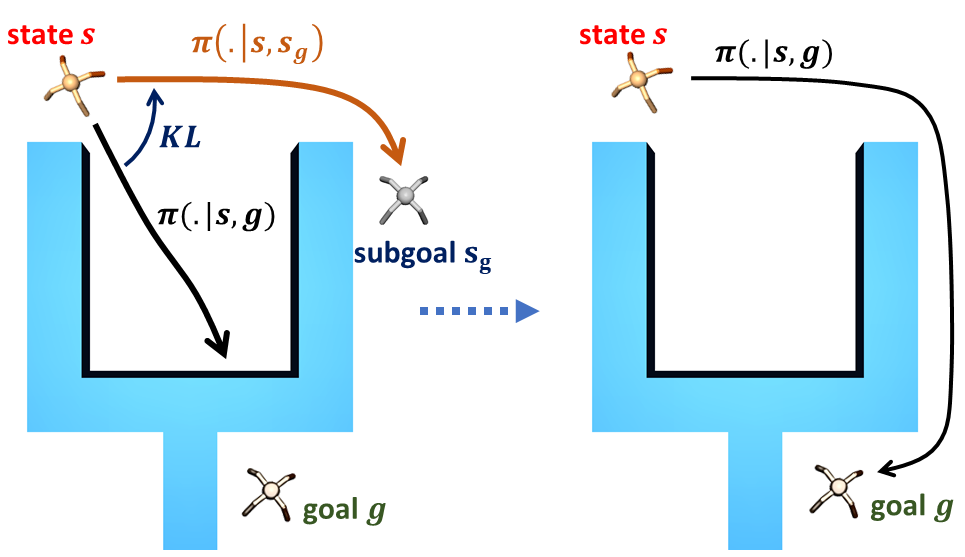
Experiments
Ant Navigation

Ant U-maze

Ant S-maze
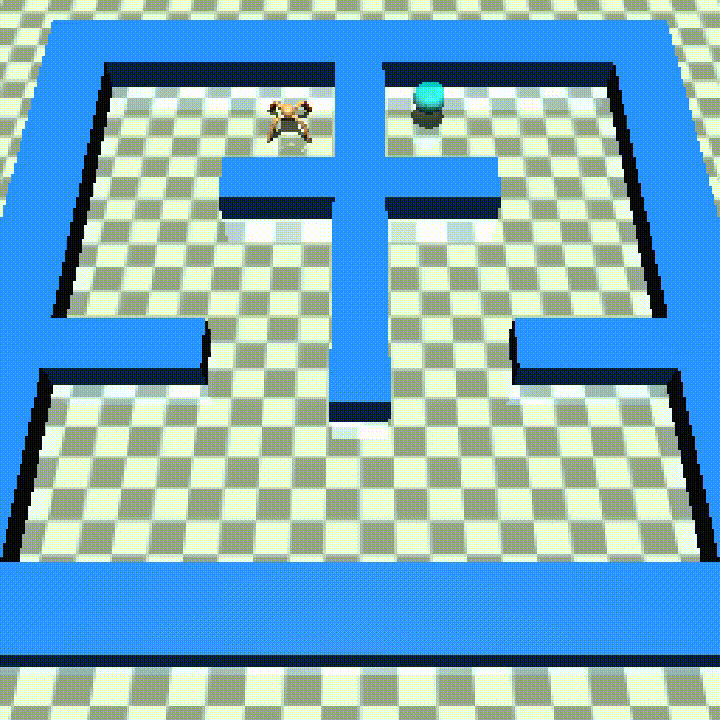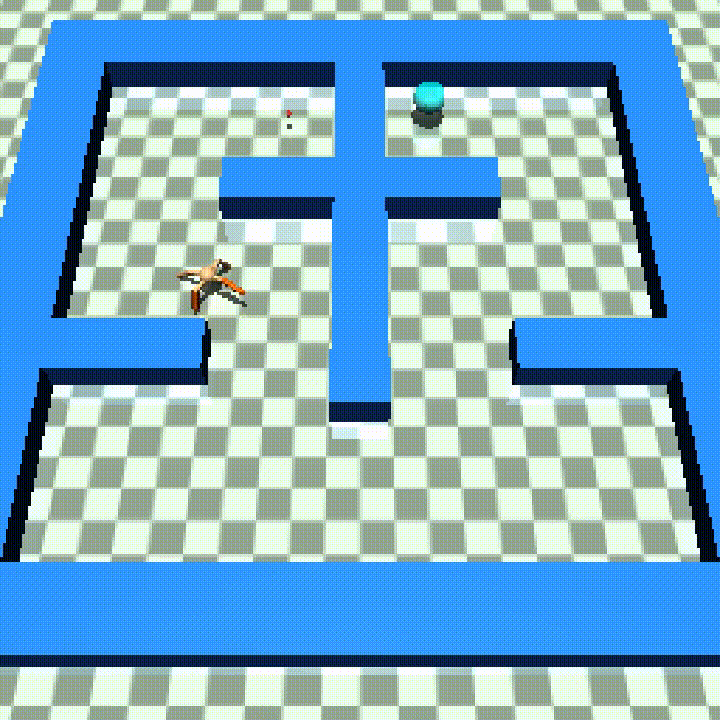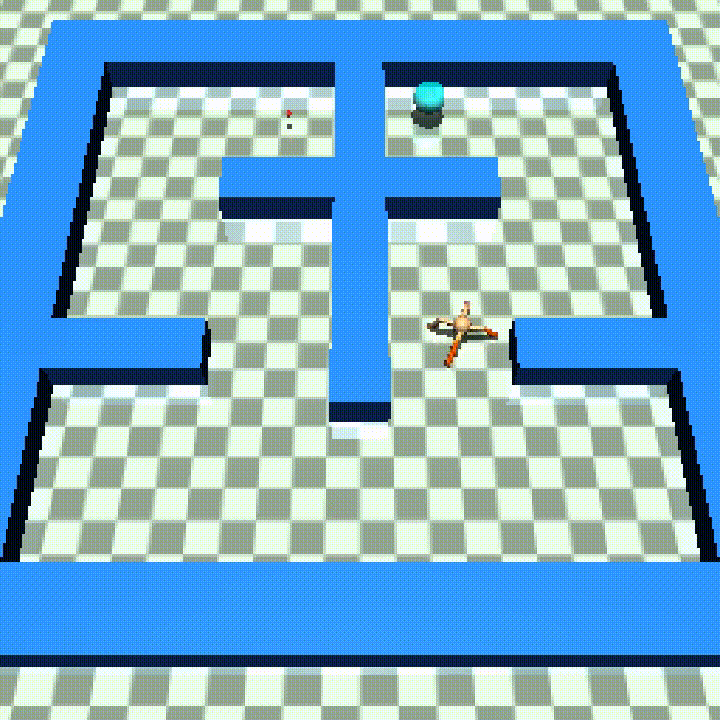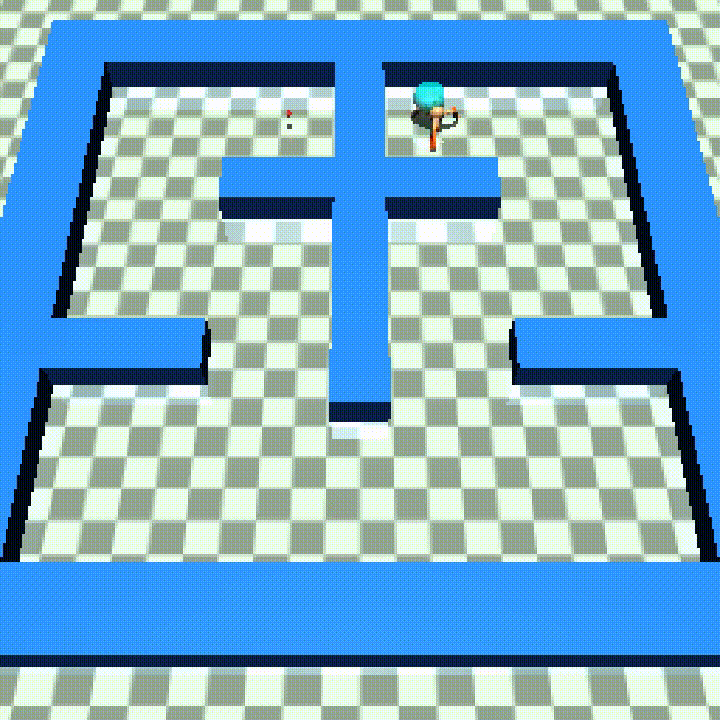
Ant π-maze

Ant ω-maze
Vision-Based Robotic Manipulation
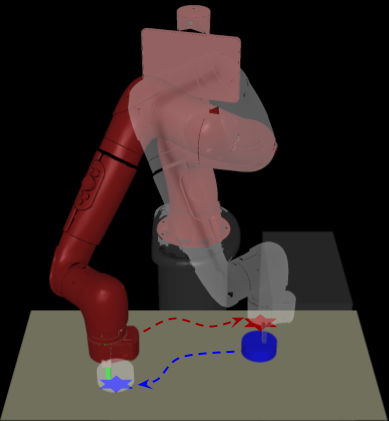
Illustration

Observation

Goal
Ant U-maze
Ant S-maze
Ant π-maze
Ant ω-maze
Illustration
Observation
Goal



Links
 github
github
Citation
@inproceedings{chanesane2021goal,
author = {Elliot Chane-Sane and Cordelia Schmid and Ivan Laptev},
title = {Goal-Conditioned Reinforcement Learning with Imagined Subgoals},
year = {2021},
Booktitle = {ICML}
}
