| HOME | PROJECTS | PUBLICATIONS | DOWNLOAD | CONTACT | CVART |
|
||
| Space-Time Interest Points (STIP): | ||
Earlier version: |
Update 2011-01-20:
Release of updated STIP code. Includes compiled 64bit Linux binaries for space-time interest point
detector and descriptor. New in this version: computes HOGHOF descriptors at a dense grid of
space-time points or user-defined set of space-time points coming e.g. from a customer interest point detector.
The code has been used in
"Evaluation of local spatio-temporal features for action recognition" (2009), | |
| Hollywood-2 Human Actions and Scenes dataset (CVPR09) | ||
|
Hollywood-2 datset contains 12 classes of human actions and 10 classes of scenes distributed over 3669 video clips and approximately 20.1 hours of video in total. The dataset intends to provide a comprehensive benchmark for human action recognition in realistic and challenging settings. The dataset is composed of video clips extracted from 69 movies, it contains approximately 150 samples per action class and 130 samples per scene class in training and test subsets. A part of this dataset was originally used in the paper "Actions in Context", Marszałek et al. in Proc. CVPR'09. Hollywood-2 is an extension of the earlier Hollywood dataset. | |
| Hollywood Human Actions dataset (CVPR08) | ||
Hollywood dataset contains video samples with human action from 32 movies. Each sample is labeled according to one or more of 8 action classes: AnswerPhone, GetOutCar, HandShake, HugPerson, Kiss, SitDown, SitUp, StandUp. The dataset is divided into a test set obtained from 20 movies and two training sets obtained from 12 movies different from the test set. The Automatic training set is obtained using automatic script-based action annotation and contains 233 video samples with approximately 60% correct labels. The Clean training set contains 219 video samples with manually verified labels. The test set contains 211 samples with manually verified labels. More details on the dataset can be obtained here. The dataset was originally used in the paper "Learning Realistic Human Actions from Movies", Ivan Laptev, Marcin Marszałek, Cordelia Schmid and Benjamin Rozenfeld; in Proc. CVPR'08. See on-line paper description here. | ||
| Drinking & Smoking action annotaion (ICCV07) | ||
Annotation for action classes "Drinking" and "Smoking" in the movies "Coffee and Cigarettes" (2003) - Jim Jarmusch, "Sea of love" (1989) - Harold Becker and in the drinking video dataset recorded at INRIA/Vista. The annotation describes each action by a cuboid in space-time, a keyframe and the position of the head on the keyframe. The annotation summary is available here. We provide a Matlab toolkit for reading annotation data as well as the description of the experimental setup used in the paper "Retrieving actions in movies" (2007), I. Laptev and P. Pérez; in Proc. ICCV, October, Rio de Janeiro, Brazil |
||
| Object detection: | ||
2007-07-07: Latest release of object detection open source implementation of Boosted Histograms algorithm. The code is made available in collaboration with TT-Solutions. Detection on a video stream from a camera is supported providing close to real-time performance (~10fps on 320x240 images). Earlier release: objectdet20070116.zip |
||
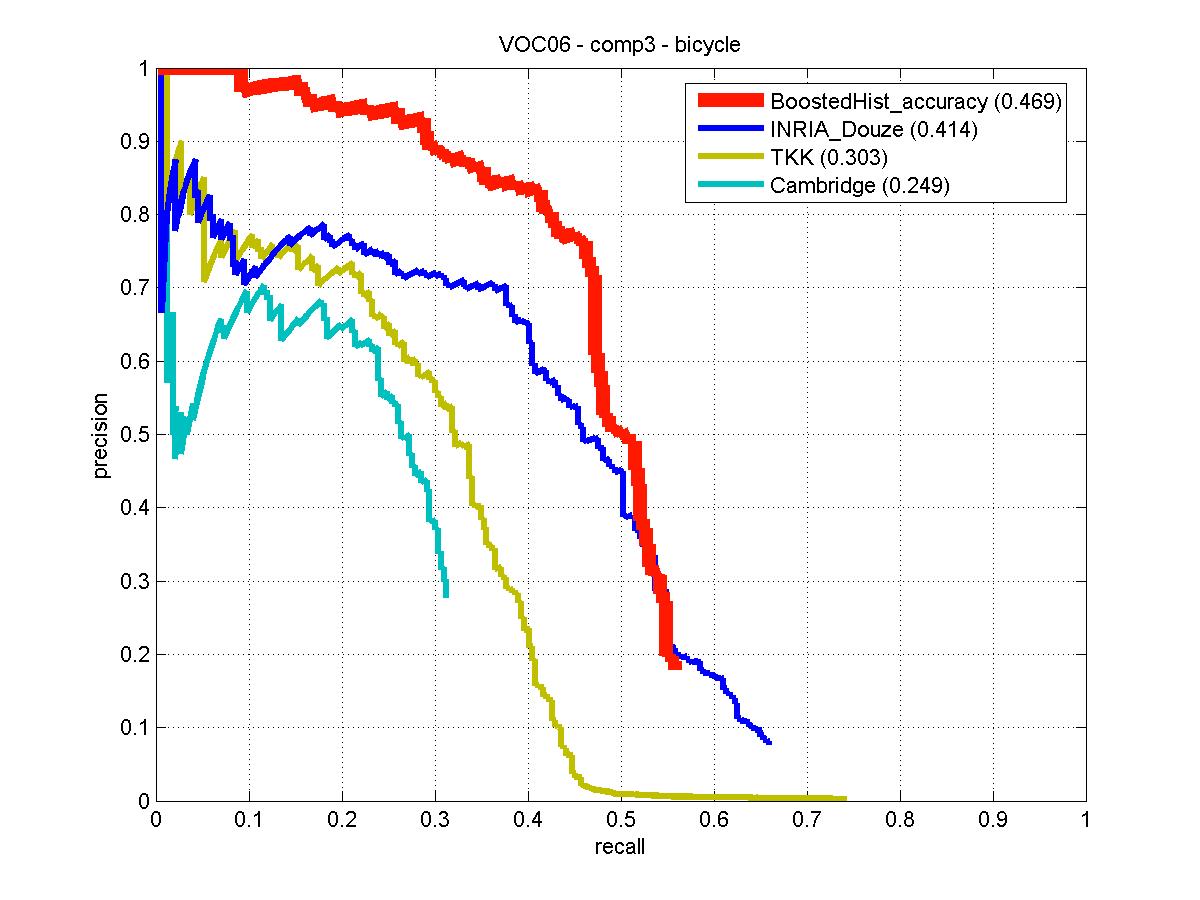
Bicycle detector trained on VOC06 training/validation data set. Detection examples along with the performance evaluation on the VOC06 test set are provided. The classifier achieves best performance for the "bicycle" class detection among other VOC06 reported methods as illustrated by precision-recall curves to the right. |
 |
|
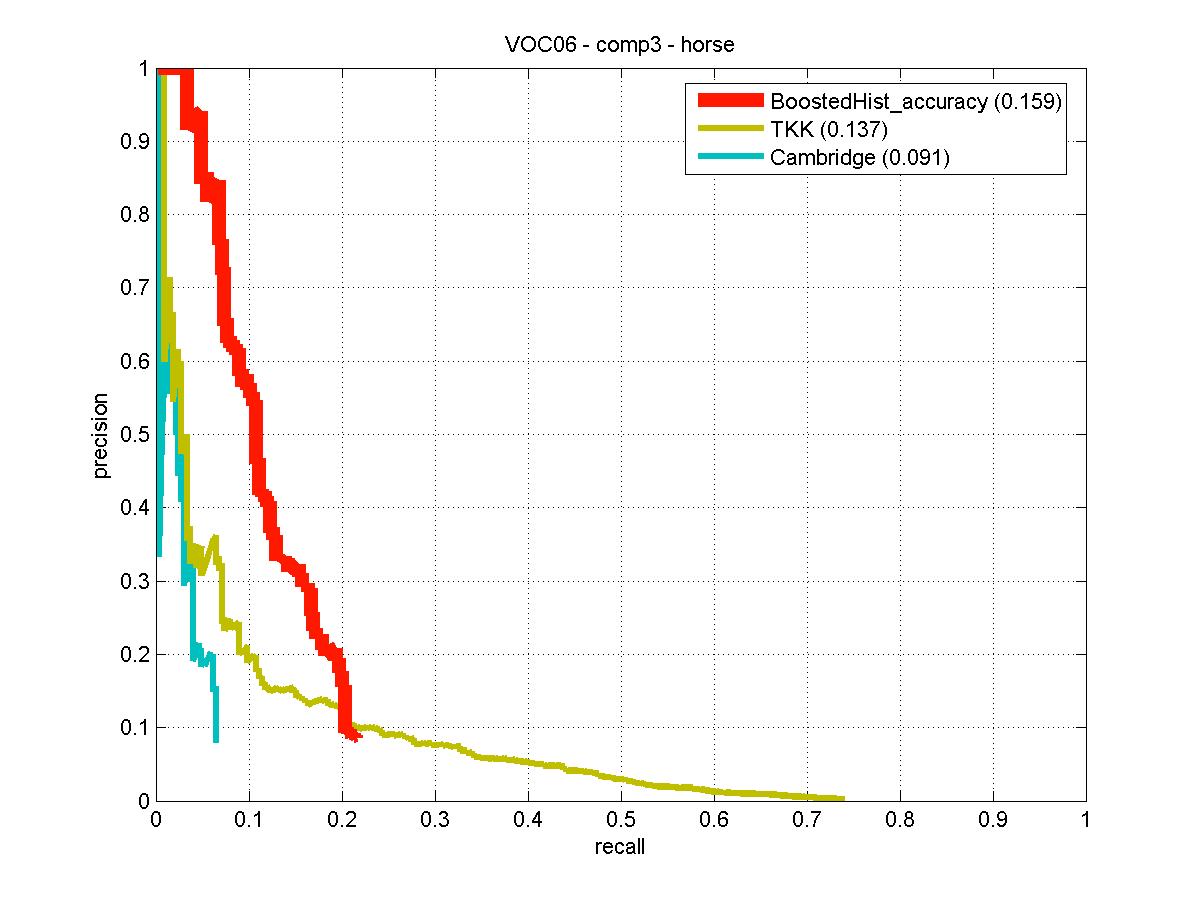
Horse detector trained on VOC06 training/validation data set. Detection examples along with the performance evaluation on the VOC06 test set are provided. The classifier achieves best performance for the "horse" class detection among other VOC06 reported methods as illustrated by precision-recall curves to the right. |
 |
|
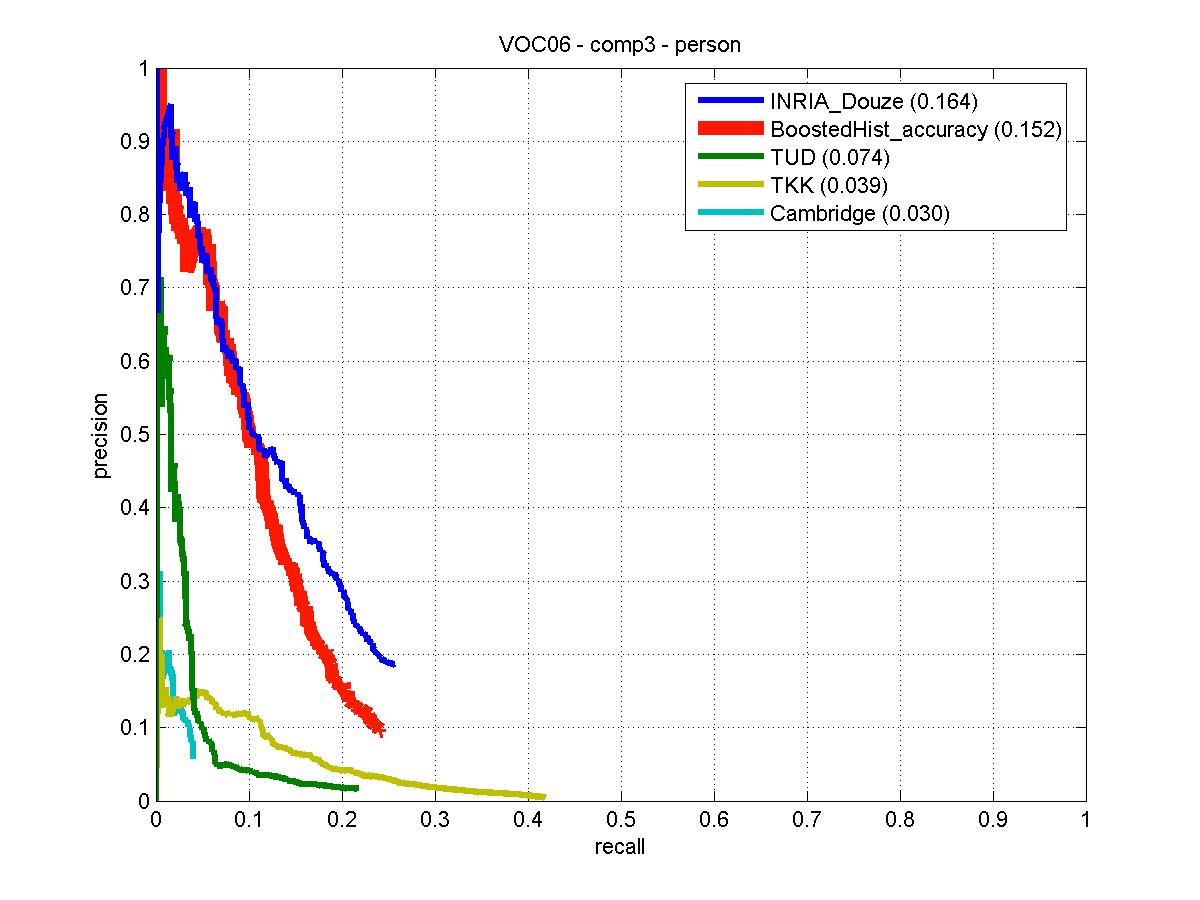
Person detector trained on VOC06 training/validation data set. Detection examples along with the performance evaluation on the VOC06 test set are provided. The classifier achieves the second-best performance for the "person" class detection among other VOC06 reported methods as illustrated by precision-recall curves to the right. |
 |
|
Cat Face detector trained on VOC06 training/validation cat images with additional manual cat face annotation. Detection examples are provided. |
||







