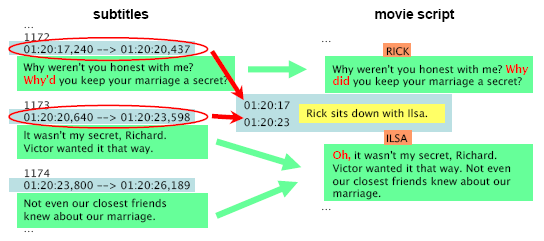
| HOME | PROJECTS | PUBLICATIONS | DOWNLOAD | CONTACT | CVART |
|
||||||||||
|
Joint work by I.Laptev, M.Marszałek, C.Schmid, and B.Rozenfeld |
||||||||||
|
[Download: CVPR08 paper | Movie actions dataset | Dataset description | STIP features code ] |
||||||||||
|
|
|||||||||
|
Video representation |
||||||||||
 |
We describe each video segment using
Space-time interest points (STIP).
Interest points are detected for a fixed set of multiple spatio-temporal scales
as illustrated on the left for a sample of the HandShake action.
For each interest point we compute descriptors of the associated space-time
patch. We compute two alternative patch descriptors in terms of (i) histograms of
oriented (spatial) gradient (HOG) and (ii) histograms of optical flow (HOF).
Our local descriptors concatenate several histograms from a space-time grid defined on the
patch and generalize
SIFT descriptor
to space-time.
We build a visual vocabulary of local space-time descriptors and assign each
interest point to a visual word label.
|
|||||||||
|
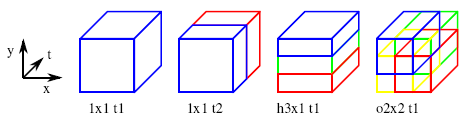
We represent each video sequence by histograms of visual word occurrences over a space-time volume corresponding either to the entire video sequence (Bag-of-Features (BoF) representation) or multiple subsequences defined by a video grid. A few of our video grids are illustrated to the right. Each combination of a video grid with either HOG or HOF descriptor is called a channel. |
 |
|||||||||
|
Action classification |
||||||||||
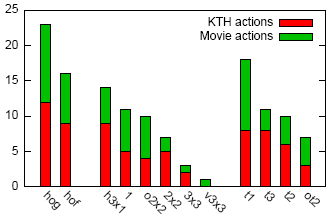 |
For classification, we use a non-linear support vector machine with a multi-channel kernel. We first select the overall most successful channels and then choose the most successful combination of channels for each action class individually. Figure to the left illustrates the number of occurrences of channel components in the channel combinations optimized for KTH actions dataset and our movie action dataset. We observe that HOG descriptors are chosen more frequently than HOFs, but both are used in many channels. Among the grids, BoF representations are selected most frequently for movie actions. Finer grids such as horizontal 3x1 partitioning and 3-bin temporal grids are frequently selected for the KTH dataset. The observed behavior is consistent with the fact that KTH dataset is more structured in space-time compared to our movie actions dataset. |
|||||||||
|
Classification results |
||||||||||
|
We validate our action recognition method on KTH actions dataset. The results to the right demonstrate a significant improvement achieved by our method when compared to other recently reported results on the same dataset and using the same experimental settings. |
 |
|||||||||
|
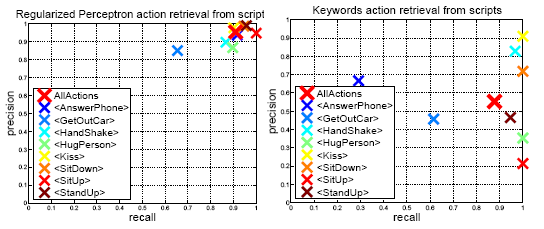
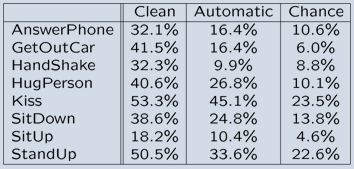
We report recognition results for 8 classes of realistic human actions when training on action samples from 12 movies and testing on samples from 20 different movies. We used two alternative training sets. The Automatic training set was constructed using automatic action annotation method (see above) and contains over 60% correct action labels. The Clean training set was obtained by manually correcting the Automatic set. Recognition results for both training sets when using the same set for testing are illustrated to the right and show significantly better performance compared to chance. Our annotated human actions dataset HOHA (2.4Gb) is available for download. |
 |
|||||||||
|
Action classification demo
|
||||||||||
|
||||||||||
Further details Paper: Slides: Download: |
||||||||||