Exercice 1 - Pyramide des ages
Le fichier Ages.txt contient le recensement de la population de Paris en 2007 (selon l'INSEE). Les résultats sont regroupés arrondissement par arrondissement et affiche sur une ligne la catégorie d'âge (de 0 à 14 ans, de 15 à 29 ans, ...) et sur la ligne suivante le nombre d'hommes et de femmes appartenant à cette catégorie (les deux valeurs étant séparées par une espace).
Écrire un script Python chargeant le fichier dans deux array à deux dimensions (un par sexe) associant aux catégorie d'âge et aux arrondissements le nombre d'habitants correspondants.
-
Modifier le script pour qu'il calcule la population totale de Paris par catégorie d'âge.
-
Modifier le script pour qu'il trouve l'arrondissement le plus jeune, le plus agé, le plus masculin et le plus féminin (en moyenne sur la population de l'arrondissement).
-
Modifier le script pour qu'il calcule le coefficient de corrélation des âges correspondant à deux arrondissements quelconques puis qu'il affiche les arrondissements où les âges de la population sont les plus corrélés.
- Modifier le script pour qu'il affiche sous forme d'une pyramide des âges, le recensement cumulé d'une liste d'arrondissements entrée par l'utilisateur.
# -*- coding: latin-1 -*- from scipy import * from pylab import * FichierIn = open('Ages.txt','r') Ages = FichierIn.readlines() # Liste où chaque élément contient une ligne # du fichier 'Ages.txt' Categories = range(7) # Liste contenant les categories d'age TableauH = zeros([20,7]) # Tableau contenant les valeurs de l'INSEE (H) TableauF = zeros([20,7]) # Tableau contenant les valeurs de l'INSEE (F) for i in range(7): Categories[i] = Ages[2*i+2] CategorieAge = array([7,22,37,51,67,82,90]) # Tableau de l'age moyen par catégorie for i in range(20): for j in range(7): valeur = Ages[2*j+17*i+3] L = valeur.split() # convertit la chaîne de caractères en la liste # formée des deux valeurs TableauH[i,j] = int(L[0]) # int sert à convertir la chaîne en entier TableauF[i,j] = int(L[1]) print "La population totale de Paris en 2007 etait de", \ int((TableauH+TableauF).sum()), "habitants" print "La population totale de Paris en 2007 par categorie \ d'age est :" Populationparcategorie = (TableauH+TableauF).sum(axis=0) for i in range(7): print Categories[i][0:-1], ":", int(Populationparcategorie[i]), \ "habitants" NbFmoyen = TableauF.sum(axis=1)/(TableauH+TableauF).sum(axis=1) # Calcule le nombre de femmes par arrondissement divisé par # la population totale par arrondissement print "L'arrondissement le plus feminin est le", \ where(NbFmoyen == NbFmoyen.max())[0][0]+1,"eme" print "L'arrondissement le plus masculin est le", \ where(NbFmoyen == NbFmoyen.min())[0][0]+1,"eme" # affiche l'indice correspondant à la valeur maximale dans # les tableaux construits précédemment Agemoyen = zeros(20) Agemoyen = dot(TableauH+TableauF,CategorieAge)/(TableauH+TableauF).sum(axis=1) print "L'arrondissement le plus age est le", \ where(Agemoyen == Agemoyen.max())[0][0]+1,"eme" print "L'arrondissement le plus jeune est le", \ where(Agemoyen == Agemoyen.min())[0][0]+1,"eme" Correlation = corrcoef(TableauH+TableauF)-eye(20) # Soustraire la matrice identité permet de supprimer les corrélations à 1 # d'une ligne à elle même print "Les arrondissements dont les pyramides des ages sont les plus \ proches sont le", where(Correlation == Correlation.max())[0][0]+1, "eme \ et le", where(Correlation == Correlation.max())[0][1]+1,"eme" print("Affichage de la pyramides des ages des arrondissements \ de votre choix") ListeArrond = [] while True: Arr = input("Entrer un numero d'arrondissement (0 pour terminer):") if 0 < Arr < 21: ListeArrond = ListeArrond + [Arr-1] else: break # Tableau[ListeArrond] contient uniquement les lignes de ListeArrond # Il suffit donc de sommer sur les colonnes (axis = 0) title("Pyramide des ages") ValH = barh(arange(7),TableauH[ListeArrond].sum(axis=0),label="Hommes",color='b') ValF = barh(arange(7),(-1)*TableauF[ListeArrond].sum(axis=0),label="Femmes",color='r') ylabel("Ages") yticks(arange(7),Categories) xlabel("Habitants") legend((ValH[0],ValF[0]),('Hommes','Femmes')) show()
Exercice 2 - Ensemble de Mandelbrot
D'après Wikipédia
L'ensemble de Mandelbrot est une fractale qui est définie comme l'ensemble des points c du plan complexe pour lesquels la suite récurrente définie par : zn+1 = zn2 + c et la condition z0 = 0 ne tend pas vers l'infini (en module). Si nous reformulons cela sans utiliser les nombres complexes, en remplaçant zn par le couple (xn, yn) et c par le couple (a, b) alors nous obtenons: xn+1 = xn2 - yn2 + a et yn+1 = 2xnyn + b.
Il peut être démontré que dès que le module de zn est strictement plus grand que 2 (zn étant sous forme algébrique, quand xn2 + yn2 > 2), la suite diverge vers l'infini, et donc c est en dehors de l'ensemble de Mandelbrot. Cela nous permet d'arrêter le calcul pour les points ayant un module strictement supérieur à 2 et qui sont donc en dehors de l'ensemble de Mandelbrot. Pour les points de l'ensemble de Mandelbrot, i.e. les nombres complexes c pour lesquels zn ne tend pas vers l'infini, le calcul n'arrivera jamais à terme, donc il doit être arrêté après un certain nombre d'itérations déterminé par le programme.
Écrire un script qui affiche (une approximation de) l'ensemble de Mandelbrott.
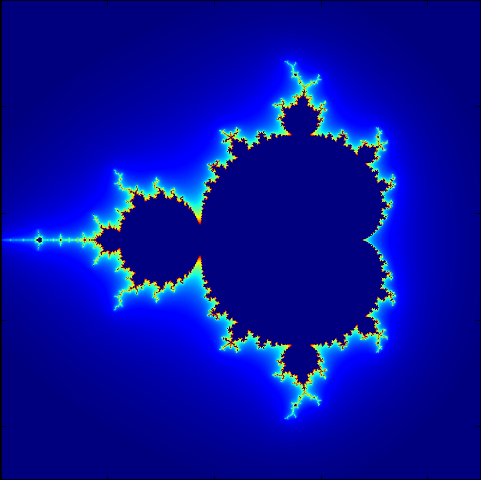
from scipy import * import pylab def mandelbrot(h, w, maxit=15): x = linspace(-3,1.5,w) y = array(matrix(linspace(-1.5,1.5,h)).T) c = x + y*1j z = c.copy() divtime = maxit + zeros((h, w), dtype=int) restant = ones((h, w), dtype=bool) # for i in range(maxit): z[restant] = z[restant]*z[restant] + c[restant] # Mise a jour des points restants div = abs(z*restant) > 2 # Matrice booleene indiquant la divergence divtime[div] = i # Mise a jour du temps de divergence restant &= ~div # Mise a jour des points restants z = z**2 + c # Lissage pour une figure plus jolie z = z**2 + c divtime = divtime + 2 - log(log(abs(z) + 1))/log(2) return divtime M = (mandelbrot(900, 1350, 30)/30*768).astype(int) M[(M >= 768) | (M < 0)] = 0 pylab.imshow(M) pylab.show()