|
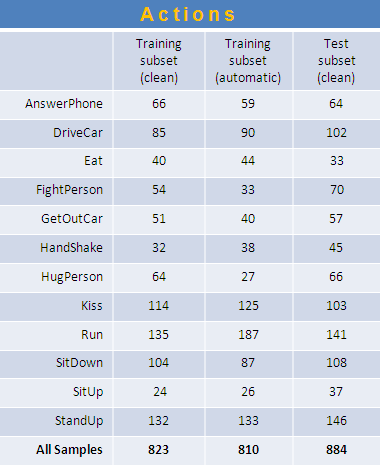
Action
samples were collected by means of automatic script-to-video alignment
in combination with text-based script classification following
Laptev at al. CVPR'08.
Video samples generated from training movies correspond to the automatic training subset
with noisy action labels. Based on this subset we also constructed a clean training subset
with action labels manually verified to be correct. We also provide a test subset with manually
checked action labels.
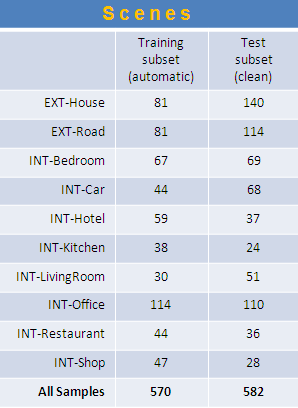
Scene classes are selected automatically from scripts such as to maximize co-occurrence with the given action
classes and to capture action context as described in
Marszałek et al. CVPR'09. Scene video samples are then generated using script-to-video alignment.
The labels of test scene samples are manually verified to be correct.
The following tables provide the numbers of video samples in each of the subsets as well as the
distributions of class instances in each subset. Note that samples may contain instances of several actions such
e.g. kissing and hugging.
|