Dictionnaire
Les programmes de correction orthographique ont besoin de
tester rapidement si un mot fait partie du dictionnaire ou non, ainsi
que d'ajouter facilement des mots au dictionnaire. Une version simple de
dictionnaire s'obtient par une représentation
arborescente. L'arbre représentant le dictionnaire comporte des noeuds
dont le nombre de fils est variable. Chaque noeud représente une lettre
(de type char) d'un mot du dictionnaire et a pour
fils les lettres pouvant arriver immédiatement derrière.
Pour une recherche plus efficace, ces fils sont classés par ordre alphabétique.
Le dictionnaire lui-même est (un pointeur sur) la
liste des initiales de mots. Comme pour les chaînes de caractères en C, le
caractère '\0' indique la fin d'un mot. Cela est nécessaire
pour savoir quels préfixes d'un mot forment des mots du dictionnaire.
Pour représenter des arbres dont le nombre de fils peut varier, nous allons
utiliser des arbres binaires interprétés de façon un peu particulière.
L'idée est la suivante : chaque noeud de l'arbre binaire N est
le fils d'un autre noeud P(sauf pour la racine). Le fils droit de
N dans l'arbre binaire correspond au fils suivant de P dans
l'arbre de départ, et le fils gauche de N dans l'arbre binaire
correspond au premier de ses fils dans l'arbre de départ. Dans le cas du
dictionnaire, donc, le fils droit est un
pointeur vers une autre lettre possible en même position et le fils gauche est
un pointeur vers la suite possible du mot.
Les choses seront plus claires sur un exemple...
Exemple
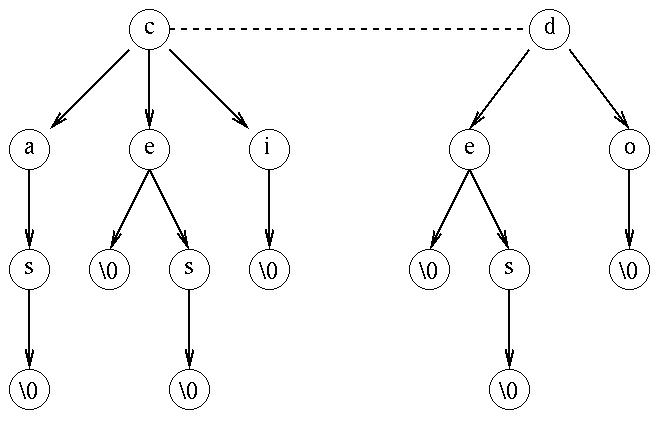
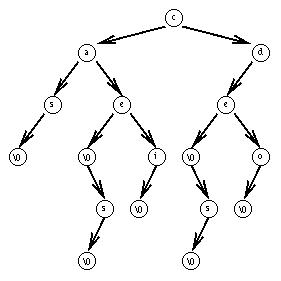
Si le dictionnaire
se compose des mots ``cas'', ``ce'', ``ces'', ``ci'', ``de'' ``des'' et ``do'',
l'arborescence sera la suivante :
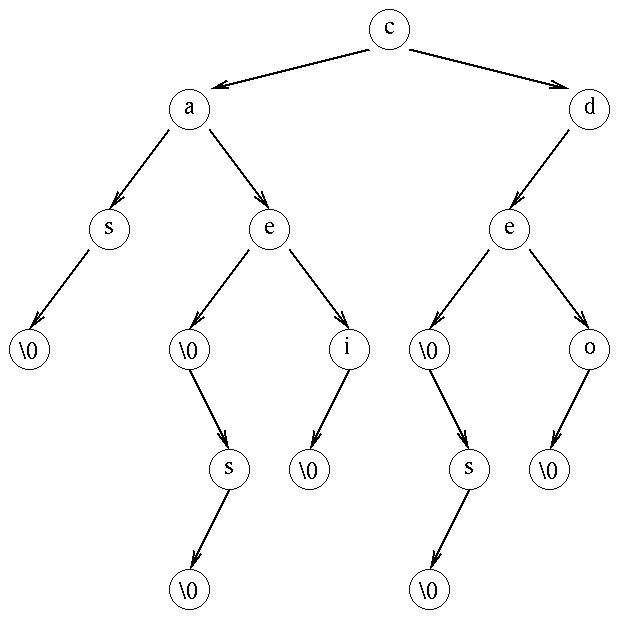
Pour traduire en arbre binaire, il suffit de bouger certaines flèches :
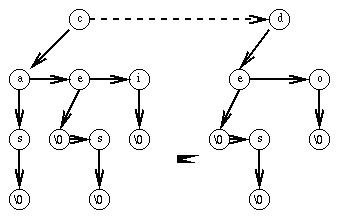 Puis, de tourner un peu l'arbre pour avoir une vision d'arbre binaire
classique :
Puis, de tourner un peu l'arbre pour avoir une vision d'arbre binaire
classique :
 Descendre vers la gauche correspond à passer à la lettre
suivante dans le corps d'un mot ; descendre vers la droite
correspond à passer à une autre lettre en même position.
Descendre vers la gauche correspond à passer à la lettre
suivante dans le corps d'un mot ; descendre vers la droite
correspond à passer à une autre lettre en même position.
Dans cet exemple, le caractère '\0'
permet de
dire que ``ce'' est un mot
en même temps qu'une partie de ``ces'', alors que ``ca'' n'est pas
un mot, mais seulement une partie de ``cas''.
Notez bien que pour une plus grande efficacité, les lettres qui se suivent de
fils droit en fils droit sont ordonnés.
Types
Un dictionnaire sera donc représenté par un arbre
étiqueté par des char. On pourra donc utiliser les
types de données définis au
TP 3 :
arbre et son constructeur noeud.
Manipulation du dictionnaire
- 1.
- Écrire une fonction
qui prend en arguments un mot et un dictionnaire et détermine
si oui ou non le mot est dans le dictionnaire ;
- 2.
- Écrire une fonction qui
crée un dictionnaire réduit à un mot ;
- 3.
- Écrire une fonction qui prend en arguments un mot et
un dictionnaire, et renvoie le dictionnaire enrichi de ce mot. Cette
fonction pourra utiliser la fonction précédente ;
Création du dictionnaire
Le dictionnaire sera créé à partir d'un fichier contenant
les mots du dictionnaire, un par ligne. On utilisera les fonctions
d'entrée sortie de haut niveau de la librairie stdio.h.
Pour ouvrir un fichier en lecture, utiliser fopen(fichier,"r")
et pour le fermer, fclose(file). La fonction fopen
renvoie un FILE * qui est utilisé pour les fonctions de lecture.
Pour lire les caractères, on peut utiliser fgetc(file).
Par exemple, une boucle pour lire tous les caractères d'un fichier :
int c;
FILE *file;
file = fopen("fichier","r"); //ou a la place de "fichier" une variable char *
while( (c=fgetc(file))!=EOF ){
/* faite de c ce que vous voulez
*/
}
fclose(file);
- 4.
- Écrire une fonction
int lire_ligne(FILE *f, char *buffer) qui lit une ligne entière et
met le mot correspondant dans buffer (sans oublier le
\0 final). Attention à la mémoire !
- 5.
- Écrire une fonction qui lit les mots dans un fichier
et retourne le dictionnaire correspondant. Tester sur un petit
fichier (et imprimer le résultat
si vous avez écrit la procédure
imprime_arbre au
précédent TP).
- 6.
- Écrire une fonction qui demande des mots à
l'utilisateur et vérifie leur présence dans le dictionnaire.
On rappelle que le
FILE * de l'entrée standard est
stdin (voir stdio.h)..
On pourra tester le programme sur des dictionnaires plus conséquents,
par exemple le dictionnaire d'anglais de /usr/dict/words, ou le
dictionnaire de francais de /usr/local/util/lib/words.french.
Corrigé
Compaction du dictionnaire
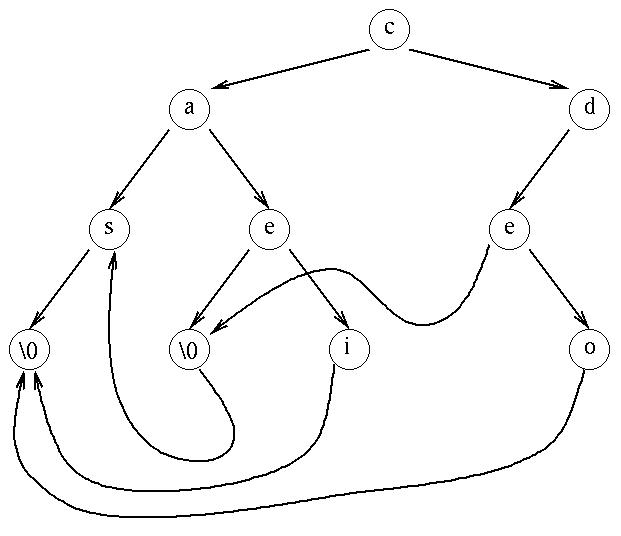
Il est possible de réduire l'espace mémoire
occupé par un arbre binaire en partageant les
sous-arbres communs. Chaque fois que deux sous-arbres sont identiques,
l'un d'entre eux est détruit et remplacé par l'autre.
Dans le cas du dictionnaire, la représentation arborescente permet de
partager les préfixe, et la compaction permet de partager les suffixes.
Exemple
Le dictionnaire précédent compacté :
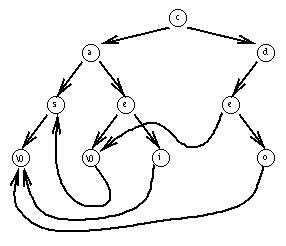
Algorithme de compaction
La nouvelle structure de données s'appelle un DAG pour Directed
Acyclic Graph. Ce n'est pas exactement un arbre, mais on peut utiliser
exactement le même type de données, arbre, et
les mêmes algorithmes de recherches de mots sans aucune modification.
La seule chose à faire est donc de compacter le dictionnaire grâce
à une fonction de compaction qui prend un arbre en argument et retourne
un ``arbre''. Cette fonction compacte le fils droit et le fils gauche, puis
cherche dans une liste si un sous-arbre avec le même label et les
mêmes fils a déjà été rencontré. Si
c'est la cas, elle retourne le sous-arbre déjà rencontré,
sinon, elle en crée un nouveau qu'elle rajoute à la liste
avant de le retourner.
- 7.
- L'algorithme de compaction utilise une liste de sous-arbres.
Écrire le type correspondant, ainsi que ses fonctions de construction.
- 8.
- Écrire la fonction de compaction récursive.
- 9.
- Écrire la fonction de compaction du dictionnaire qui
initialise la liste de sous-arbres, appelle la fonction récursive et
vide la liste des sous-arbres après usage. Tester sur un
dictionnaire (pas trop gros...) et imprimer le nombre de noeuds gagnés
par la compaction.
Étant donné la structure de données
utilisée pour stocker les sous-arbres déjà
rencontrés, le temps de compaction grandit très vite avec la
taille du dictionnaire. Il est possible d'améliorer substantiellement
le temps de recherche dans la liste des sous-arbres en la divisant en plusieurs
listes disjointes. L'idée est qu'on peut facilement, étant
donné un sous-arbre, trouver dans quelle sous-liste il doit se trouver.
Un facon de procéder consiste à séparer la liste selon
la hauteur des sous-arbres. On rappelle que la hauteur d'un arbre est 0 pour
un arbre vide, et 1 + la plus grande des hauteurs de ses fils sinon.
- 10.
- Modifier les fonctions de compaction pour qu'elles utilisent un
tableau de listes de sous-arbres au lieu d'une simple liste. La liste
numéro i ne sera remplie qu'avec des arbres de hauteur
i. Tester, cette fois sur un gros dictionnaire.
Pour améliorer encore la vitesse de compaction, on peut
remplacer la recherche dans la liste des sous-arbres par une structure
permettant une recherche plus rapide. On pourra essayer un arbre binaire de
recherche ou une table de hachage (voir les fonctions de
search.h). Dans les deux cas, il faudra encore
associer un entier à chaque sous-arbre.
Compaction à la volée
- 11.
- Plutôt que de construire le dictionnaire puis de le compacter, il
est mieux de le construire déjà compacté. Indication : il suffit de
modifier légèrement le constructeur pour ne construire que des noeuds
unique, les autres algorithmes restant inchangés...