Learning Video-Conditioned Policies
for Unseen Manipulation Tasks
IEEE International Conference on Robotics and Automation (ICRA), 2023
Abstract
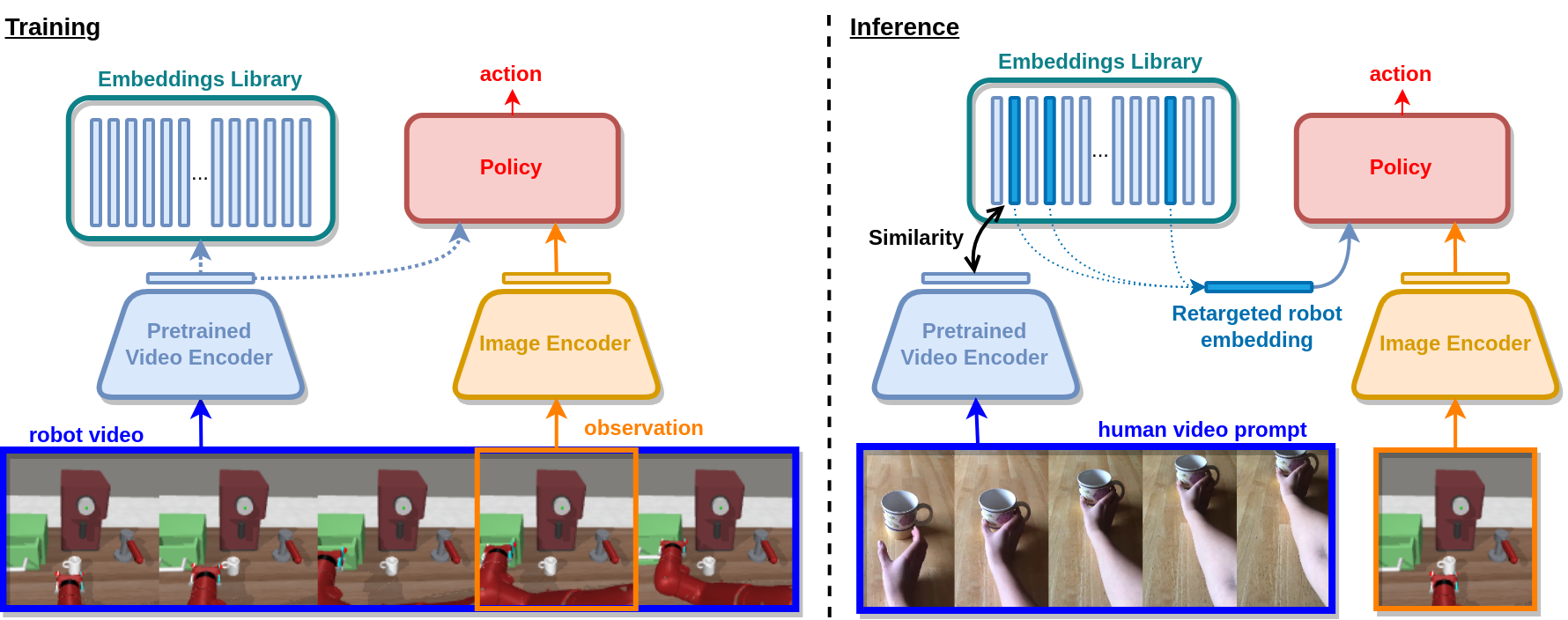
The ability to specify robot commands by a non-expert user is critical for building generalist agents capable of solving a large variety of tasks. One convenient way to specify the intended robot goal is by a video of a person demonstrating the target task. While prior work typically aims to imitate human demonstrations performed in robot environments, here we focus on a more realistic and challenging setup with demonstrations recorded in natural and diverse human environments. We propose Video-conditioned Policy learning (ViP), a data-driven approach that maps human demonstrations of previously unseen tasks to robot manipulation skills. To this end, we learn our policy to generate appropriate actions given current scene observations and a video of the target task. To encourage generalization to new tasks, we avoid particular tasks during training and learn our policy from unlabelled robot trajectories and corresponding robot videos. Both robot and human videos in our framework are represented by video embeddings pre-trained for human action recognition. At test time we first translate human videos to robot videos in the common video embedding space, and then use resulting embeddings to condition our policies. Notably, our approach enables robot control by human demonstrations in a zero-shot manner, i.e., without using robot trajectories paired with human instructions during training. We validate our approach on a set of challenging multi-task robot manipulation environments and outperform state of the art. Our method also demonstrates excellent performance in a new challenging zero-shot setup where no paired data is used during training.



Links
Paper
arXivCode
 Available soon
Available soon
Citation
@inproceedings{chanesane2023vip,
author = {Elliot Chane-Sane and Cordelia Schmid and Ivan Laptev},
title = {Learning Video-Conditioned Policies for Unseen Manipulation Tasks},
year = {2023},
Booktitle = {ICRA}
}
