For being compatible with the first version, image files can also be named with 4 digits, namely, printf("%04d.jpg", i) or printf("%04d.ppm", i). The software first checks the 8-digit name then the 4-digit one, for each image.
-------------------------------------------
CONTOUR
P[0][0] P[0][1] P[0][2] P[0][3]
P[1][0] P[1][1] P[1][2] P[1][3]
P[2][0] P[2][1] P[2][2] P[2][3]
-------------------------------------------
"CONTOUR" is just a header. P[3][4] denotes a 3x4 projection matrix, which is defined as follows. Let (x y z 1) denote a homogeneous 3D coordinate of a point, and (u v 1) denote a homogeneous 2D coordinate of its image projection, then (x y z 1) and (u v 1) are related by the following equation:
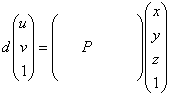
d is the depth of the point with respect to the camera. Note that the origin of the image coordinate system is at the top left corner of an image (strictly speaking, the origin lies in the center of the pixel at the top-left corner of an image). The x-axis points to the right and the y-axis points to the bottom. So, the 2D image coordinate of the top left pixel is (0, 0), and the 2D image coordinate of the bottom right pixel is (w, h), where w and h are the image width and height, respectively.
| Name | Default value | Explanations |
| timages | Must specify | timages
refers to target images.
The software tries to reconstruct 3D points until image
projections of these points cover all the target images (only
foreground pixels if segmentation masks are given) specified in this
field (also see an explanation for the parameter csize). There are 2 ways to
specify such images.
|
| oimages | Must specify | oimages refers to other images (sorry for a stupid naming), which also specifies image indexes that are used for reconstruction. However, the difference from timages is that the software keeps reconstructing points until they cover all timages, but not oimages. In other words, oimages are simply used to improve accuracy of reconstructions, but not to check the completeness of reconstructions. There are two ways to specify oimages, which are the same as timages. Note that if you do not need oimages, just have a line "oimages 0". |
| level | 1 | The software internally builds an image pyramid, and this parameter specifies the level in the image pyramid that is used for the computation. When level is 0, original (full) resolution images are used. When level is 1, images are halved (or 4 times less pixels). When level is 2, images are 4 times smaller (or 16 times less pixels). In general, level = 1 is suggested, because cameras typically do not have r,g,b censors for each pixel (bayer pattern). Note that increasing the value of level significantlly speeds-up the whole computation, while reconstructions become significantly sparse. |
| csize | 2 | csize (cell size) controls the density of reconstructions. The software tries to reconstruct at least one patch in every csize x csize pixel square region in all the target images specified by timages. Therefore, increasing the value of csize leads to sparaser reconstructions. Note that if a segmentation mask is specified for a target image, the software tries to reconstruct only foreground pixels in that image instead of the whole. |
| threshold | 0.7 | A patch reconstruction is accepted as a success and kept, if its associcated photometric consistency measure is above this threshold. Normalized cross correlation is used as a photometric consistency measure, whose value ranges from -1 (bad) to 1 (good). The software repeats three iterations of the reconstruction pipeline, and this threshold is relaxed (decreased) by 0.05 at the end of each iteration. For example, if you specify threshold=0.7, the values of the threshold are 0.7, 0.65, and 0.6 for the three iterations of the pipeline, respectively. |
| wsize | 7 | The software samples wsize x wsize pixel colors from each image to compute photometric consistency score. For example, when wsize=7, 7x7=49 pixel colors are sampled in each image. Increasing the value leads to more stable reconstructions, but the program becomes slower. |
| minImageNum | 3 | Each 3D point must be visible in at least minImageNum images for being reconstructed. 3 is suggested in general. The software works fairly well with minImageNum=2, but you may get false 3D points where there are only weak texture information. On the other hand, if your images do not have good textures, you may want to increase this value to 4 or 5. |
| CPU | 4 | The software supports threading, and you can specify the number of (virtual) CPUs in your machine. For example, if you have dual dual-core Xeon. You should set CPU=4. |
| useVisData | 0 | Sometimes, you know
the relations of input images (visibility information). For
example, if you use Structure-from-Motion software to estimate camera
parameters, you roughly know which images should be used together to
reconstruct points. PMVS can exploit such an information by creating a
file named "vis.dat" under root,
and set useVisData=1.
This can significantly speed-up the computation and it is highly recommented to use this information if available. vis.dat should start with a line "VISDATA". The second line should
contain the number of images in the dataset, followed by the same
number of lines till the end of the file. From the third line, a single
line contains the visibility information of an input image in an
increasing order of image indexes. For example, the 3rd line
contains the information for image 0, 4th line contains the information
for image 1, etc. Each line should start with a dummny integer, which is not actually used by the software, but you can, for example, put an image index to make it easy for you to look at the files. Again this first number in each line is not used by the software, and lines contain information for images in an increasing order of indexes. This could be very confusing. After the dummy integer, there should be another integer representing the number of images that will be used together in reconstructing points. Then, indexes of such images should follow. Image relations specified in vis.dat should be symmetric. Lastly, I will use a simple example in the following to explain the format. Suppose you have the following vis.dat under root: ---------------------------------- VISDATA 5 -2342 2 1 2 3425 3 0 2 3 232 2 0 1 -28 2 1 4 5123 1 3 ---------------------------------- This vis.dat file specifies the following. -2342 2 1 2 --> Image 0 will be used with images 1 and 2 to reconstruct points. 3425 3 0 2 3 --> Image 1 will be used with images 0, 2 and 3 to reconstruct points. 232 2 0 1 --> Image 2 will be used with images 0 and 1 to reconstruct points. -28 2 1 4 --> Image 3 will be used with images 1 and 4 to reconstruct points. 5123 1 3 --> Image 4 will be used with image 3 to reconstruct points. Of course, the first number in each line shouldn't be random, and you can, for example, specify an image index with the number to make it easy for you to read the file. The following file will contain the same information as the example above. ---------------------------------- VISDATA 5 0 2 1 2 1 3 0 2 3 2 2 0 1 3 2 1 4 4 1 3 ---------------------------------- |
| sequence | -1 | Sometimes, images are given in a sequence, in which case, you can enforce the software to use only images with similar indexes to reconstruct a point. sequence gives an upper bound on the difference of images indexes that are used in the reconstruction. More concretely, if sequence=3, image 5 can be used with images 2, 3, 4, 6, 7 and 8 to reconstruct points. |
| quad | 2.5 | The software removes spurious 3D points by looking at its spatial consistency. In other words, if 3D oriented points agree with many of its neighboring 3D points, the point is less likely to be filtered out. You can control the threshold for this filtering step with quad. Increasing the threshold is equivalent with loosing the threshold and allows more noisy reconstructions. Typically, there is no need to tune this parameter. |
| maxAngle | 10 | Stereo algorithms require certain amount of baseline for accurate 3D reconstructions. We measure baseline by angles between directions of visible cameras from each 3D point. More concretely, a 3D point is not reconstructed if the maximum angle between directions of 2 visible cameras is below this threshold. The unit is not in radian, but in degrees. Decreasing this threshold allows more reconstructions for scenes far from cameras, but results tend to be pretty noisy at such places. |