Paper

J. Lezama, K. Alahari, J. Sivic, I. Laptev
Track to the Future: Spatio-temporal Video Segmentation with Long-range Motion Cues
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2011)
PDF |
Abstract |
BibTeX |
Poster
Abstract
Video provides not only rich visual cues such as motion and appearance, but
also much less explored long-range temporal interactions among objects. We aim
to capture such interactions and to construct powerful intermediate-level video
representation for subsequent recognition. Motivated by this goal, we seek to
obtain spatio-temporal over-segmentation of the video into regions that respect
object boundaries and, at the same time, associate object pixels over many
video frames. The contributions of this paper are two-fold. First, we develop
an efficient spatio-temporal video segmentation algorithm, which naturally
incorporates long-range motion cues from the past and future frames in the form
of clusters of point tracks with coherent motion. Second, we devise a new track
clustering cost-function that includes occlusion reasoning, in the form of
depth ordering constraints, as well as motion similarity along the tracks. We
evaluate the proposed approach on a challenging set of video sequences of
office scenes from feature length movies.
BibTeX
@InProceedings{lezama11,
author = {Lezama, J. and Alahari, K. and Sivic, J. and Laptev, I.},
title = {Track to the Future: Spatio-temporal Video Segmentation with Long-range Motion Cues},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year = {2011}
}
Dataset

Overview
The goal of this work is to provide a spatio-temporal segmentation of videos,
i.e. a segmentation that is consistent with object boundaries and
associates object pixels over time. For example, given a video sequence such
as the one in the figure (a) below (shown as a three frames from the video
sequence), the goal is to generate a segmentation shown in the figure (b)
below, where the scene is divided into two foreground regions consisting of
two people -- one walking and the other sitting -- and the background region.
 |  |
| (a) | (b) |
Sample frames from a video sequence, and their corresponding segmentations into three regions.
We propose a method for unsupervised spatio-temporal
segmentation of videos, which is a building block for many other tasks such
as object and human action recognition in videos. Whilst there have been
many attempts to address the segmentation problem, they are restricted to
only a local analysis of the video. Our method uses point tracks to capture
long-range motion cues, and also infers local depth-ordering to separate
objects. We build on the graph-based agglomerative segmentation work of
[Felzenszwalb and Huttenlocher 2004, Grundmann et al. 2010], and group
neighbouring pixels with similar colour and motion. Our framework is
summarized in the figure below:
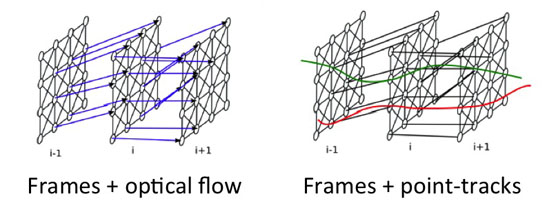
Pixels in one image frame are connected to corresponding pixels in the next frame using optical flow. We also introduce point-tracks for long-range support over time and encourage all pixels in a track to belong to the same segment. We ensure that dissimilar tracks are assigned to different segments.
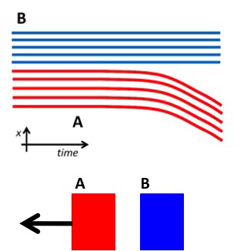
We illustrate the benefits of using long-range point
tracks with the following two examples. In the first example below, we
consider two objects A (the moving object) and B (the stationary object).
The point tracks corresponding to these objects are shown in (a) below. If
one were to only use short term motion analysis (in the initial frames),
the two objects would be merged into one segment. However, by observing
the entire length of the point track, we note that the two objects belong
to different segments. Using this (dis)similarity constraint on our video
example leads to track clustering shown in (b) below.
 |  |
| (a) | (b) |
Using motion (dis)similarity to cluster point-tracks in our example video.
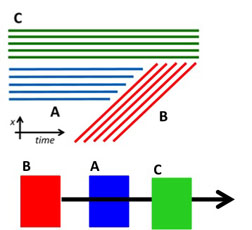
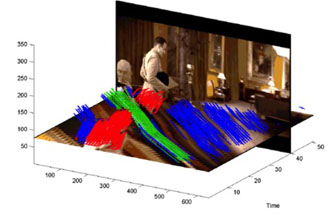
Although the above result is reasonable, it does not
separate the sitting person from the background. In the second example below,
we consider three objects B (the moving object), A and C (the stationary
objects). Object B moves in front of object A, but behind object C. Thus,
the point tracks corresponding to objects A and C should belong different
segments. This toy example corresponds to our example video, where "object"
A is the background, object B is the walking person, and object C is the
sitting person. We use such local depth-ordering constraints on our video
example to obtain the track clustering shown in (b) below.
 |  |
| (a) | (b) |
Using local depth-ordering constraints separates objects. In (b), the sitting person is separated from the background.
We formulate the point track clustering problem as an energy
function, and solve it using Sequential Tree-reweighted message passing
algorithm [Kolmogorov 2005]. Further details can be found in our paper.
Additional results and videos will be available here soon.
Acknowledgements
This work was partly supported by the Quaero Programme, funded by OSEO, and by the MSR-INRIA laboratory.