 |
Figure 1. An example of region-based semantic matching and dense matching.
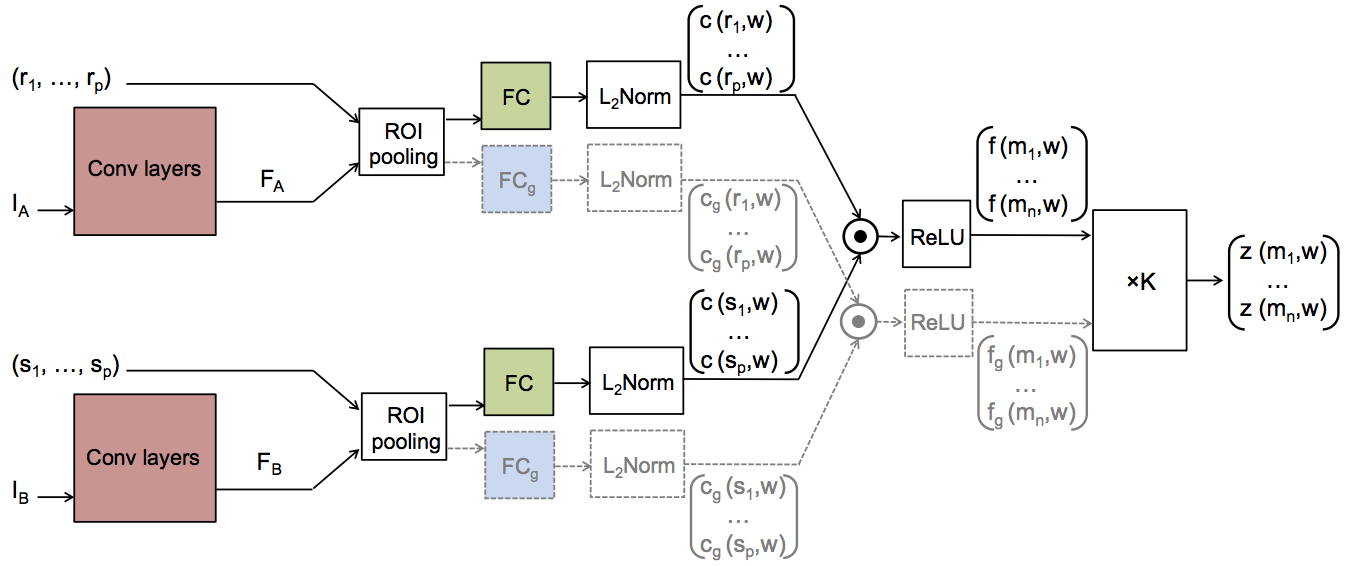 |
Figure 2. The SCNet architectures. Three variants are proposed: SCNet-AG, SCNet-A, and SCNet-AG+. The basic architecture,
SCNet-AG, is drawn in solid lines. Colored boxes represent layers with learning parameters and the boxes with the same
color share the same parameters. “×K” denotes the voting layer for geometric scoring. A simplified variant, SCNet-A, learns
appearance information only by making the voting layer an identity function. An extended variant, SCNet-AG+, contains an
additional stream drawn in dashed lines.
Abstract
This paper addresses the problem of establishing semantic correspondences between images depicting different instances of the same object or scene category. Previous approaches focus on either combining a spatial regularizer with hand-crafted features, or learning a correspondence model for appearance only. We propose instead a convolutional neural network architecture, called SCNet, for learning a geometrically plausible model for semantic correspondence. SCNet uses region proposals as matching primitives, and explicitly incorporates geometric consistency in its loss function. It is trained on image pairs obtained from the PASCAL VOC 2007 keypoint dataset, and a comparative evaluation on several standard benchmarks demonstrates that the proposed approach substantially outperforms both recent deep learning architectures and previous methods based on hand-crafted features.
Paper

Kai Han, Rafael S. Rezende, Bumsub Ham, Kwan-Yee K. Wong, Minsu Cho, Cordelia Schmid, Jean Ponce
SCNet: Learning Semantic Correspondence
International Conference on Computer Vision (ICCV), 2017
PDF | arXiv | BibTeX

SCNet: Learning Semantic Correspondence
International Conference on Computer Vision (ICCV), 2017
PDF | arXiv | BibTeX
Code & Data
SCNet: Learning Semantic Correspondence
The demo code of SCNet and its benchmark system implemented in MATLAB.
GitHub page
The demo code of SCNet and its benchmark system implemented in MATLAB.
GitHub page
Acknowledgements
This work was supported by the ERC grants VideoWorld and Allegro, the Institut Universitaire de France, and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. 2017R1C1B2005584). We gratefully acknowledge the support of NVIDIA Corporation with the donation of a Titan X Pascal GPU used for this research. We also thank JunYoung Gwak and Christopher B. Choy for their help in comparing with UCN.Last updated: July 2017