Overview


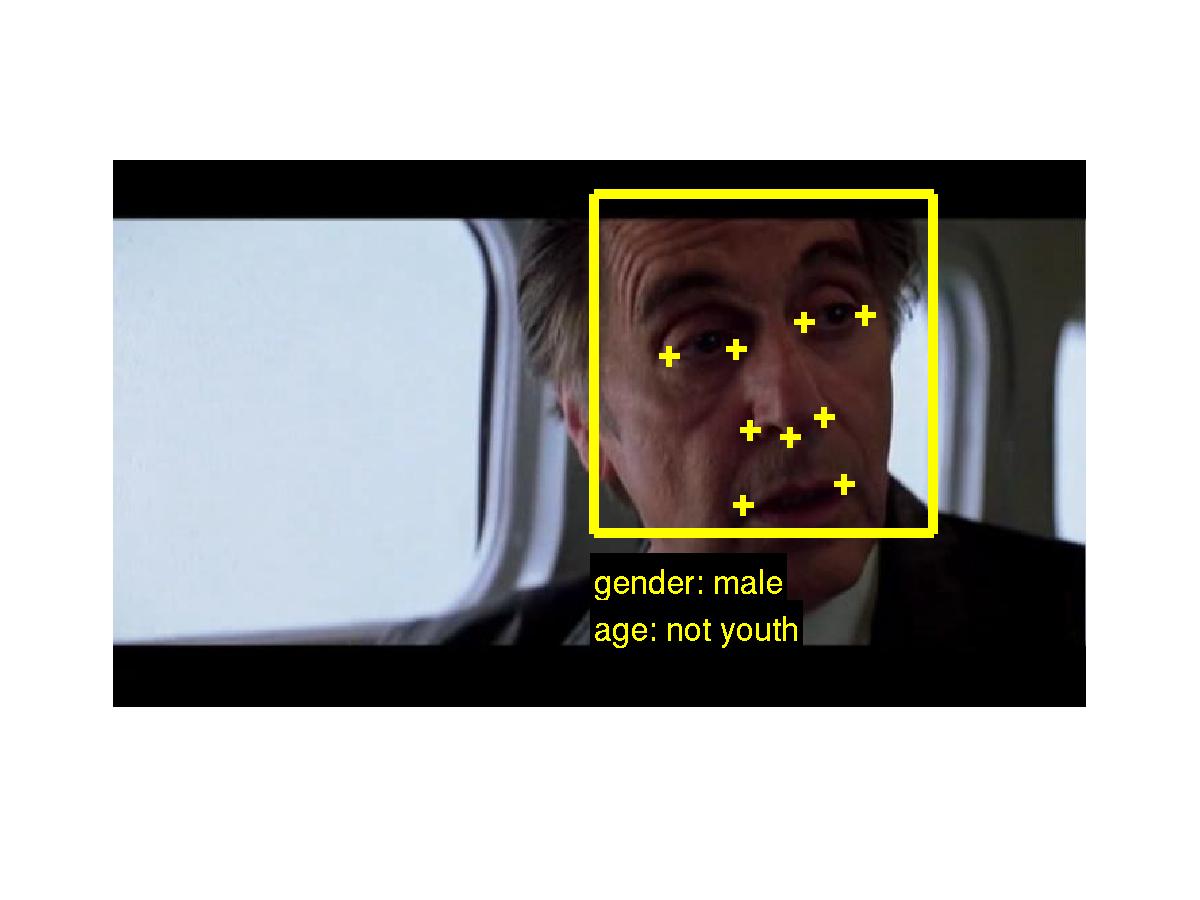
This annotated data set contains ground truth labels of face tracks of six different movies. The tracks are labeled with gender (female/male) and age (youth/not youth). The movie Love, Actually contains additional labels that we do not yet use in our testing.
We ran our tracking algorithm over all detected faces and eliminated non-faces manually. We provide the full set of true face tracks for completeness: 5359 training tracks and 2690 testing tracks. However, for our training and testing sets, we further restricted the data to faces for which the facial feature confidence score was high (above 0).
For our testing set, we additionally manually labeled some attributes as difficult. We do not test on difficult tracks. An attribute is considered difficult if it is hard for a human to determine the attribute from the best single frame in that track. For example, if the face is very small or blurry, it might be difficult to determine the age or gender of the person. It is also often difficult to determine the gender of a child. These restrictions are reflected in the second half of the demo Matlab script, which shows how to load the training and testing splits. The total number of training tracks we use is 3660 and the total number of testing tracks is 1532. The numbers below are based on this more restrictive set.
The track labels structure has the following fields: labels, a struct with the labels for the face (gender, age, etc); difficult, a boolean indicating if this is a difficult track to classify; and inds, a list of the indices in the face detections structure that this track corresponds to.
We also provide a face detection structure. The face detection structure has the following fields: frame, corresponding to the frame number of the video; conf, representing the facial feature confidence; rect, the bounding box of the face; pts, the
The file movie_data.zip has six subfolders, corresponding to the six different movies. Within each movie folder, there are subfolders corresponding to the VOB from which the detections were calculated. Each VOB has a face detection file and a track labels file as well as three image files for alignment. Running the script demo.m with different movie and VOB names will load the three images and draw the bounding box, facial feature points, and annotation for the associated track.
The demo file also shows how to extract a descriptor from the facial feature points. For this it relies on the other code in the distribution, which is provided courtesy of the Visual Geometry Group at Oxford. The facial feature descriptor is by Everingham et al. Further information on how it is calculated can be found in their papers and their face processing pipeline code.
The second half of the demo file shows how we create training and testing splits from the data. As described above, we only use face tracks whose minimum facial feature confidence score is greater than 0.
For further details, please see our paper from the Parts and Attributes workshop at ECCV 2010.
| Movie | Face tracks | % Female | % Youth |
|---|---|---|---|
| The Graduate | 398 | 46.2% | 53.0% |
| Roman Holiday | 1040 | 39.7% | 28.0% |
| When Harry Met Sally | 902 | 54.2% | 32.8% |
| Desperately Seeking Susan | 459 | 65.1% | 83.9% |
| Insomnia | 861 | 24.6% | 26.6% |
| Love, Actually | 1532 | 36.3% | 32.4% |