 Release 2013A This practical is on image classification, where an image is classified according to its visual content. For example, does it contain an airplane or not. Important applications are image retrieval - searching through an image dataset to obtain (or retrieve) those images with particular visual content, and image annotation - adding tags to images if they contain particular object categories. The goal of this session is to get basic practical experience with image classification. It includes: (i) training a visual classifier for five different image classes (airplanes, motorbikes, people, horses and cars); (ii) assessing the performance of the classifier by computing a precision-recall curve; (iii) varying the visual representation used for the feature vector, and the feature map used for the classifier; and (iv) obtaining training data for new classifiers using Bing image search and using the classifiers to retrieve images from a dataset. Getting startedRead and understand the requirements and installation instructions. The download links for this practical are:
After the installation is complete, open and edit the script Note: the student packages contain only the code required to run the practical. The complete package, including code to preprocess the data, is available on GitHub. Part 1: Training and testing an Image ClassifierThe data provided in the directory
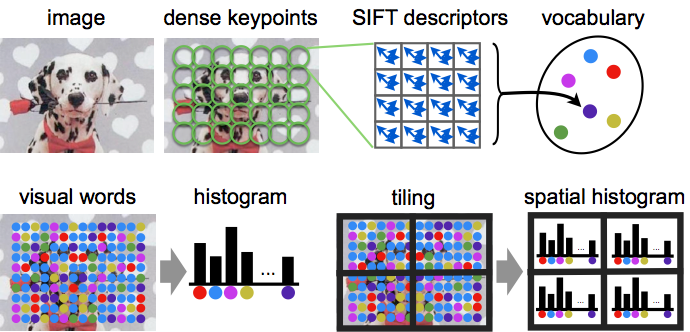
A descriptor for an image is obtained as a statistics of local image features, which in turn capture the appearance of a large number of local image regions. Mapping local features to a single descriptor vector is often regarded as an encoding step, and the resulting descriptor is sometimes called a code. Compared to sets of local features, a main benefit of working with codes is that codes can be compared by simple vectorial metrics such as the Euclidean distance. For the same reason, they are also much easier to use in learning an image classifier. In this part we will use the Bag of Visual Words (BoVW) encoding. The process of constructing a BoVW descriptor starting from an image is summarized next: First, SIFT features are computed on a regular grid across the image (`dense SIFT') and vector quantized into visual words. The frequency of each visual word is then recorded in a histogram for each tile of a spatial tiling as shown. The final feature vector for the image is a concatenation of these histograms.
We will start by training a classifier for images that contain aeroplanes. The files
The aeroplane training images will be used as the positives, and the background images as negatives. The classifier is a linear Support Vector Machine (SVM).
We will first assess qualitatively how well the classifier works by using it to rank all the training images.
You can use the function
Stage C: Classify the test images and assess the performanceNow apply the learnt classifier to the test images. Again, you can look at the qualitative performance by using the classifier score to rank all the test images. Note the bias term is not needed for this ranking, only the classification vector w.
Now we will measure the retrieval performance quantitatively by computing a Precision-Recall curve. Recall the definitions of Precision and Recall: 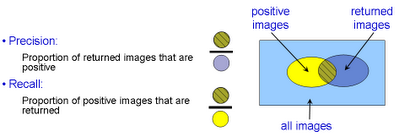 The Precision-Recall curve is computed by varying the threshold on the classifier (from high to low) and plotting the values of precision against recall for each threshold value. In order to assess the retrieval performance by a single number (rather than a curve), the Average Precision (AP, the area under the curve) is often computed.
Stage D: Learn a classifier for the other classes and assess its performance[Skip to Stage E on fast track] Now repeat Stage B and C for each of the other two classes: motorbikes and people. To do this you can simply rerun
Stage E: Vary the image representationAn important practical aspect of image descriptors is the one of their normalization. For example, BoVW descriptors are histograms, and regarding them as discrete probability distributions it would seem natural that their elements should sum to 1. This is the same as normalizing the BoVW descriptor vectors in L1 norm. However, in
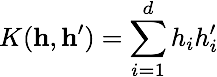 to measure the similarity between pair of objects h and h' (in this case pairs of BoVW descriptors).
[Skip to Stage F on fast track] Up to this point, the image feature vector has used spatial tiling. Now, we are going to`turn this off' and see how the performance changes. In this part, the image will simply be represented by a single histogram recording the frequency of visual words (but not taking any account of their image position). A spatial histogram can be converted back to a simple histogram by merging the tiles.
Stage F: Vary the classifierUp to this point we have used a linear SVM, treating the histograms representing each image as vectors normalized to a unit Euclidean norm. Now we will use a Hellinger kernel classifier but instead of computing kernel values we will explicitly compute the feature map, so that the classifier remains linear (in the new feature space). The definition of the Hellinger kernel (also known as the Bhattacharyya coefficient) is 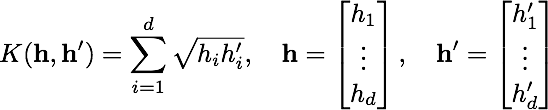 where h and h' are normalized histograms. Compare this with the expression of the linear kernel given above: all that is involved in computing the feature map is taking the square root of the histogram values.
Now we will again learn the image classifier using the Hellinger kernel instead of the linear one.
[Skip to Part 2 on fast track] Up to this point we have used all the available training images. Now edit
Part 2: Training an Image Classifier for Retrieval using Bing imagesIn Part 1 of this practical the training data was provided and all the feature vectors pre-computed. The goal of this second part is to choose the training data yourself in order to optimize the classifier performance. The task is the following: you are given a large corpus of images and asked to retrieve images of a certain class, e.g. those containing a bicycle. You then need to obtain training images, e.g. using Bing Image Search, in order to train a classifier for images containing bicycles and optimize its retrieval performance. The MATLAB code
data/cache directory. The test data also contains the category car. Train classifiers for it and compare the difficulty of this and the horse class.Part 3: Advanced Encoding Methods[Skip to end on fast track] The BoVW is an encoding of the dense SIFTs into a feature vector. One way to think about the encoding is that it aims to best represent the distribution of SIFT vectors of that image (in a manner that is useful for discriminative classification). BoVW is a hard-assignment of SIFTs to visual words, and alternative soft-assignment methods are possible where the count for a SIFT vector is distributed across several histogram bins. In this section we investigate a different encoding that records more than a simple count as a representation of the distribution of SIFT vectors. In particular we consider two encodings: one that records first moment information (such as the mean) of the distribution assigned to each Voronoi cell, and a second that records both the first and second moment (e.g. the mean and covariance of the distribution). The MATLAB code for computing these encodings in the file exercise1.m.Stage H: First order methodsThe vector of locally aggregated descriptors (VLAD) is an example of a first order encoding. It records the residuals of vectors within each Voronoi cell (i.e. the difference between the SIFT vectors and the cluster centre (from the k-means) as illustrated below: 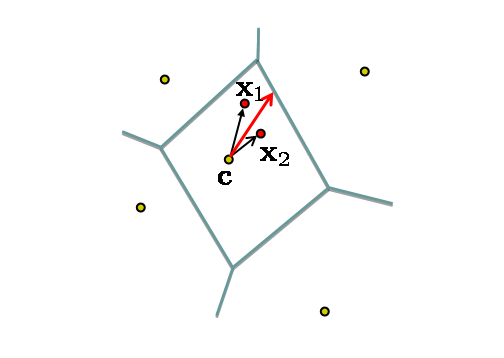 Suppose the SIFT descriptors have dimension D, then the total size of the VLAD vector is K x D (since a D-dimensional residual is recorded for each Voronoi cell). Typically, K is between 16 and 512, and D is 128 or less.
Stage I: Second order methodsThe Fisher Vector (FV) is an example of second order encoding. It records both the residuals (as in VLAD) and also the covariance of the SIFTs assigned to each Voronoi cell. Its implementation uses a Gaussian Mixture Model (GMM) (instead of k-means) and consequently SIFTs are softly assigned to mixture components (rather than a hard assignment as in BoVW). Suppose there are k mixture components and the covariance is restricted to a diagonal matrix (i.e. only the variance of each component is recorded) then the total size of the Fisher vector is 2K x d.
Links and further work
Acknowledgements
History
  |

Texte d'origine
Proposer une meilleure traduction